In the previous class we introduced the simplest problem of fitting a model to data. That is one where you have precisely known \(x\)-values (with zero uncertainty), and you have associated \(y\)-values with reliable \(y\)-directional uncertainties, and you believe that the \(y\) values are truly drawn from a narrow straight line.
Assuming that the uncertainties in the \(y\)-direction are Gaussian distributed, we derived the frequency distribution for the \(y\) values, and showed how -- in this example -- maximizing the log likelihood \(\log\mathcal{L})\) is equivalent to minimizing the \(\chi^2\) value, which is familiar to many of us. However, this is not the complete picture.
What if the \(x\) values have some uncertainty to them? It means that we don't know what the true \(x\) values are, and when we were previously calculating our \(y\) values we are assuming that we precisely knew the \(x\) values! What if we have some prior belief about the model parameters \(m\) and \(b\)?
How do we extend our model to incorporate more complexity? How do we incorporate our prior beliefs in a rigorous way? How do we account for uncertainties in the \(x\) and \(y\) directions?
Bayes' theorem
First we will introduce the Bayesian generalisation of this problem. In Bayesian inference the log likelihood \(\log\mathcal{L}\) is only one part of the problem, which quantifies the likelihood of the data, given the model. However, before evaluating any likelihood we often have some idea, or prior information about what reasonable values our parameters can have. Better yet, we may have good physical reasons for how they should be distributed, or how they should vary with each other. In Bayesian inference we incorporate that prior information in a justified, rigorous way.
Bayes' theorem is nothing complex, yet it is a miraculous equation with counter-intuitive consequences. Bayes' theorem follows directly from the rules of conditional probability, and it states that \[ P(A|B) = \frac{P(B|A)P(A)}{P(B)} \] the probability of an event \(A\) occurring given event \(B\) occurring \(P(A|B)\), is equal to the probability of event \(B\) occurring given event \(A\), \(P(B|A)\), multiplied by the probability that event \(A\) will occur \(P(A)\), all divided by the probability that event \(B\) will occur \(P(B)\).
Why is this special?
\(A\) and \(B\) don't have to be events per se. It might be easier to see how important this is if we re-cast these probabilities in terms of our unknown model parameters
\[
\newcommand\vectheta{\boldsymbol{\theta}}
\newcommand\vecdata{\mathbf{y}}
\newcommand\model{\boldsymbol{\mathcal{M}}}
\newcommand\vecx{\boldsymbol{x}}
\vectheta = \{m, b\}
\]
and the data \(\mathbf{y}\),
\[
P(\vectheta|\vecdata,\model) = \frac{P(\vecdata|\vectheta,\model)P(\vectheta|\model)}{P(\vecdata|\model)}
\]
where \(\model\) describes our knowledge of \(\vecx\), \(\mathbf{\sigma_y}\), and everything else about the model.
Now you can see that we have a justified way of calculating the probability of a model, given some data, that can include some prior beliefs about that model.
Using our shorthand nomenclature for \(\vectheta\) and \(\model\), you should recognise the \(P(\vecdata|\vectheta,\model)\) term from the previous class, where we introduced the frequency distribution \(p(y_i|x_i,\sigma_{yi},m,b)\) for a single data point \(y_i\) \[ p(y_i|x_i,\sigma_{yi},m,b) = \frac{1}{\sqrt{2\pi\sigma_{yi}^2}}\exp\left(-\frac{\left[y_i-mx_i - b\right]^2}{2\sigma_{yi}^2}\right) \quad . \] Because we assume that each data point is independent, the \(P(\vecdata|\vectheta,\model)\) term is the product of individual probabilities: \[ P(\vecdata|\vectheta,\model) = \prod_{i=1}^{N} p(y_i|x_i,\sigma_{yi},\vectheta) \quad . \]
But what of the other terms?
The left-hand side of Bayes' theorem is usually what you want, because you want to know the probability of the model, given some data. The denominator on the right-hand side of Bayes' theorem \(P(\vecdata|\model)\) (or just \(P(\vecdata)\) for short) has many names
The fully marginalised likelihood is a normalisation factor to ensure all your probability density sums to unity. It can be extremely expensive (or intractable) to calculate the fully marginalised likelihood, and in most applications you don't necessarily need it. If you only want to know what the best model parameters are, and perhaps what the uncertainties on those model parameters look like, then you don't need the fully marginalised likelihood. And most times when people think they need the fully marginalised likelihood, they don't.
So, for now, we ignore it. We will come back to the fully marginalised likelihood in later classes. But how, exactly, do we get away with ignoring it? We saw this in the previous lecture when we considered what would happen if we multiplied many near-zero probabilities together. If we calculated that on a computer we would quickly reach arithmetic underflow. Instead of multiplying many near-zero values together, we sum the logarithms of those numbers \[ \log{P(\vectheta|\vecdata,\model)} = \log{P(\vecdata|\vectheta,\model)} + \log{P(\vectheta|\model)} - \log{P(\vecdata|\model)} \quad . \] We can see that \(\log{P(\vecdata|\model)}\) is a constant that does not change with \(\vectheta\), so we can re-write this as \[ \begin{array}{ccccc} \log{P(\vectheta|\vecdata,\model)} & \propto & \log{P(\vecdata|\vectheta,\model)} & + & \log{P(\vectheta|\model)} \quad . \\ \\ \uparrow && \uparrow && \uparrow \\ \textrm{log posterior} && \textrm{log likelihood} && \textrm{log prior} \\ \textrm{probability} && && \textrm{probability} \end{array} \]
So you see that what we actually want is the log posterior probability, which is the sum of the log likelihood (as we introduced last class) and the log prior probability. If you had no prior information then the log posterior probability is exactly equivalent to the log likelihood. And usually the prior is weak relative to the likelihood. But we almost always have prior information that we can include. How do we include those prior beliefs?
Priors
To introduce a prior on some parameter we must describe what we believe the probability density looks like for that parameter. For example, the most non-informative
Uniform priors are not always a good thing. You may instead believe that some parameter is 'of order X' and describe the prior as a Gaussian that is centered on X with some large variance. That may not be a good prior, either. It's important to think about what your choice of prior means, and the impact it has on your model.
Let's do that. This process is called prior predictive checks because we are going to check that our prior predictions are sensible (and match what we expect). Let us first assume that we have a uniform prior on the slope \(m\)
\[
m \sim \mathcal{U}(0, 10)
\]
and now we will sample that distribution and plot the density in \((x, y)\) space.

The lines on this figure have evenly spaced differences in slope \(m\), but they bunch up together (at angles of \(\pm\frac{\pi}{2}\)). So even though our uniform prior is giving equal possibility to each one of these lines, it's clear that a flat prior ends up favouring very steep slopes! Who ordered that?!
For good reasons outside the scope of this class
One thing you should always remember is that your priors need to be defined before you looked at the data. You cannot look at the data -- or worse, see what kind of model parameters make a reasonable fit -- and then decide what kind of prior you want to include. Otherwise you will have evidence from the sample data coming through both the likelihood and the prior.
Now consider a parallel universe where the loud gravitational signal came second, and the weak one came first. When the weak one arrived we may have flustered over it's significance for a year before telling anyone, because our prior was that gravitational waves should exist, but we didn't know for certain.
The \(x\) values now have uncertainties, too!
Let's make things a little more complicated.
The data now have uncertainties in the \(x\)-direction and in the \(y\)-direction. For now we will assume that the uncertainties in each direction are independent (uncorrelated) of each other. How do we include these new uncertainties?
Let's plot this example, where we have uncorrelated uncertainties in \(x\) and \(y\), using the same data set as the previous class.
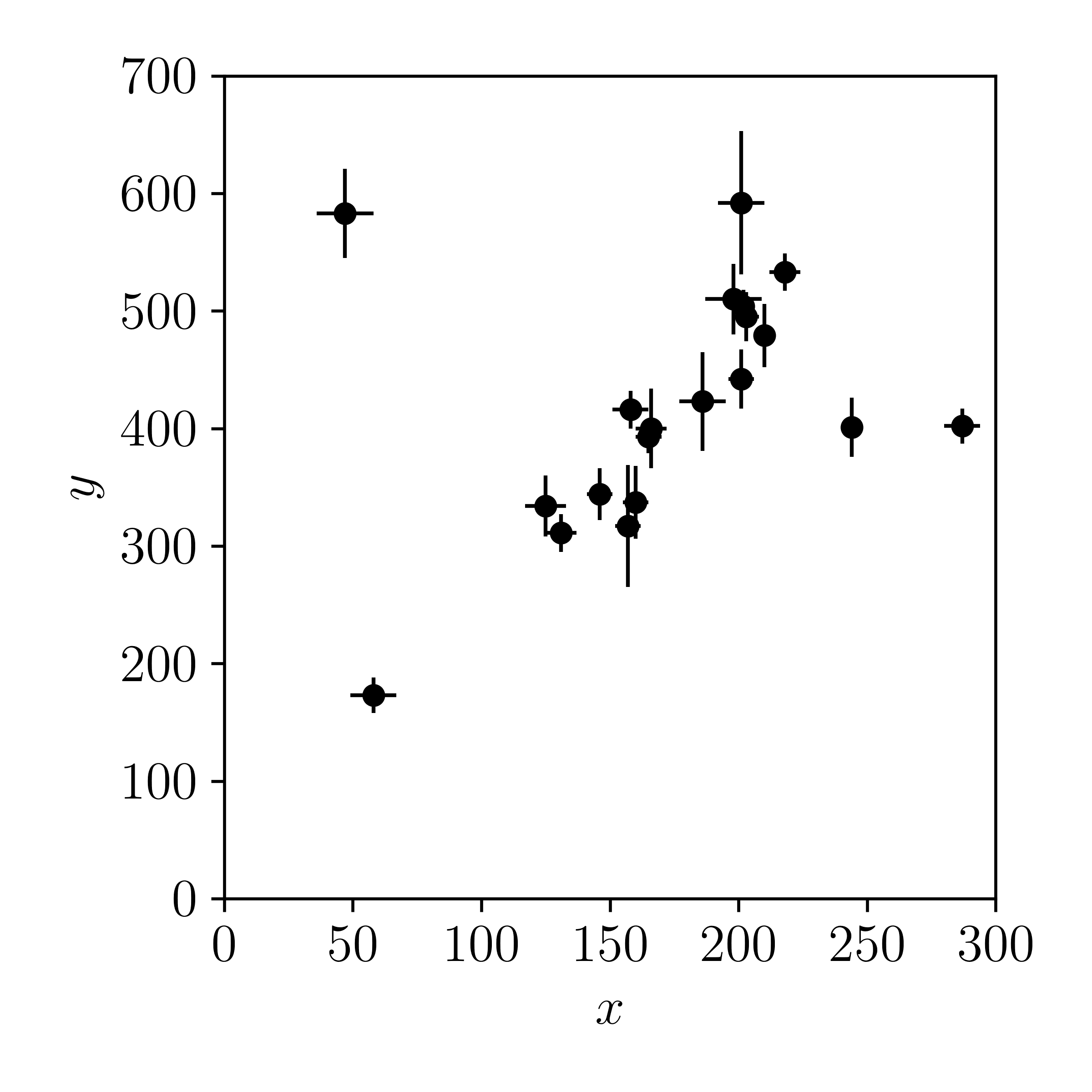
If we assume that the uncertainties in the \(x\)-direction are Gaussian distributed then the \(x_i\) value is drawn from a normal distribution (denoted with \(\mathcal{N}\)) that is centered on the true, unknown value \(\hat{x}_i\), with some standard deviation \(\sigma_{xi}\) \[ x_i \sim \mathcal{N}(\hat{x}_i, \sigma_{xi}) \quad . \]
If we were only considering the \(x\) values then the frequency distribution is already familiar to us, \[ p(x_i|\hat{x}_i,\sigma_{xi}) = \frac{1}{\sqrt{2\pi\sigma_{xi}^2}}\exp{\left(-\frac{\left[x_i - \hat{x}_i\right]^2}{2\sigma_{xi}^2}\right)} \quad . \] Because we assume the uncertainties in the \(x\)-direction and the \(y\)-direction are uncorrelated, we can calculate the joint probability of \(P(y_{i},x_{i}|\model)\) using the probability chain rule \[ P(A,B|C) = P(A|B,C)P(B|C) \] which in this context implies \[ p(y_i,x_i|\model) = p(y_i|x_i,\model)p(x_i|\model) \] and for the \(i\)-th data point, \[ p(y_i,x_i|\hat{x}_i,\sigma_{xi},\sigma_{yi},\vectheta) = p(y_i|\hat{x}_i,\sigma_{yi},\vectheta)p(x_i|\hat{x}_i,\sigma_{xi}) \quad . \]
There are a few comments worth making here. Note that the unknown true values \(\hat{x}_i\) have been lumped in with our unknown model parameters \(\vectheta\). And unlike the \(\sigma_{yi}\) values (which are known), we don't know what the \(\hat{x}_i\) values are! We have just effectively introduced \(N\) unknown parameters to represent the true values \(\hat{\vecx}\). That seems totally crazy because we have increased the number of unknown parameters from \(2\) to \(2 + N\), and all we want to do is fit a line! Now we have more unknown model parameters than we have data points! But actually, this is the simplest way to incorporate our uncertainty in the \(x\) positions, because we will marginalise over the true values \(\hat{x}_i\) (i.e., we will integrate them out) so that our constraints on \(\vectheta\) are marginalised over all possible \(\hat{\vecx}\) values.
Let's consider a single data point \((x_i, y_i)\) and marginalise over \(\hat{x}_i\) for that point. Recall that
\[
p(\phi) = \int p(\phi|\theta)p(\theta) d\theta
\]
and for a single data point this integral brings us back to the two-dimensional case
\[
p(y_i,x_i|\sigma_{xi},\sigma_{yi},\vectheta) = \int p(y_i,x_i|\hat{x}_i,\sigma_{xi},\sigma_{yi},\vectheta) p(\hat{x}_i) d\hat{x}_i
\]
where \(p(\hat{x}_i)\) is our prior on the true value \(\hat{x}_i\). We will assume an improper uniform prior
The resulting integral is a magical consequence of the fact that the convolution of a Gaussian with a Gaussian is a Gaussian
Incredible, right!? Even with our prior, the \(x\) uncertainties enter very simply into our log probability function, yet this is only because the \(x\) and \(y\) uncertainties are uncorrelated! But how would we find the best fitting model parameters? We can't solve this function using linear algebra like we did in the previous class. Instead we will minimise the negative log likelihood
Ok, let's plot the optimised solution and see how it compares to our linear algebra result from the previous class.
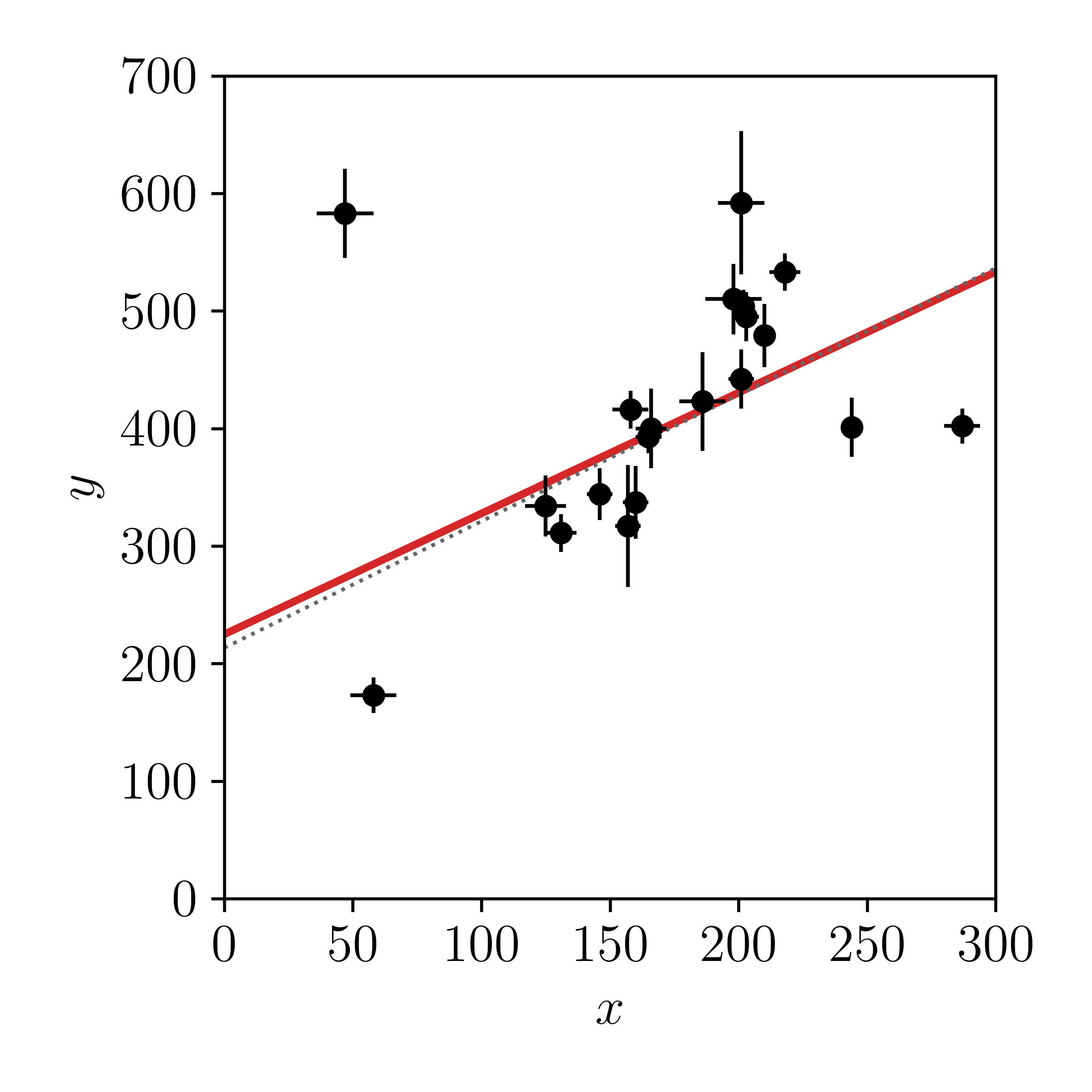
It would seem that our prior and the \(x\) uncertainties have made very little difference to our point estimate of the line parameters. The linear algebra solution from lesson one is shown in grey and our new estimate is shown in red. But this is just a point estimate: a single value estimate of the model parameters. It's possible that our uncertainties on the model parameters have now changed since including the prior on \(m\) and the \(x\) uncertainties. The prior we have adopted means we can't estimate the uncertainties from linear algebra, but we can estimate the uncertainties using Markov Chain Monte Carlo (MCMC) sampling. We will cover MCMC in a later class, so for now you can just think of it as 'an expensive way to estimate uncertainties.'

Our uncertainties have changed! Introducing the \(x\) direction uncertainties has clearly had a large effect on our inferences about the line parameters \(m\) and \(b\).
Let's plot draws from the posterior.
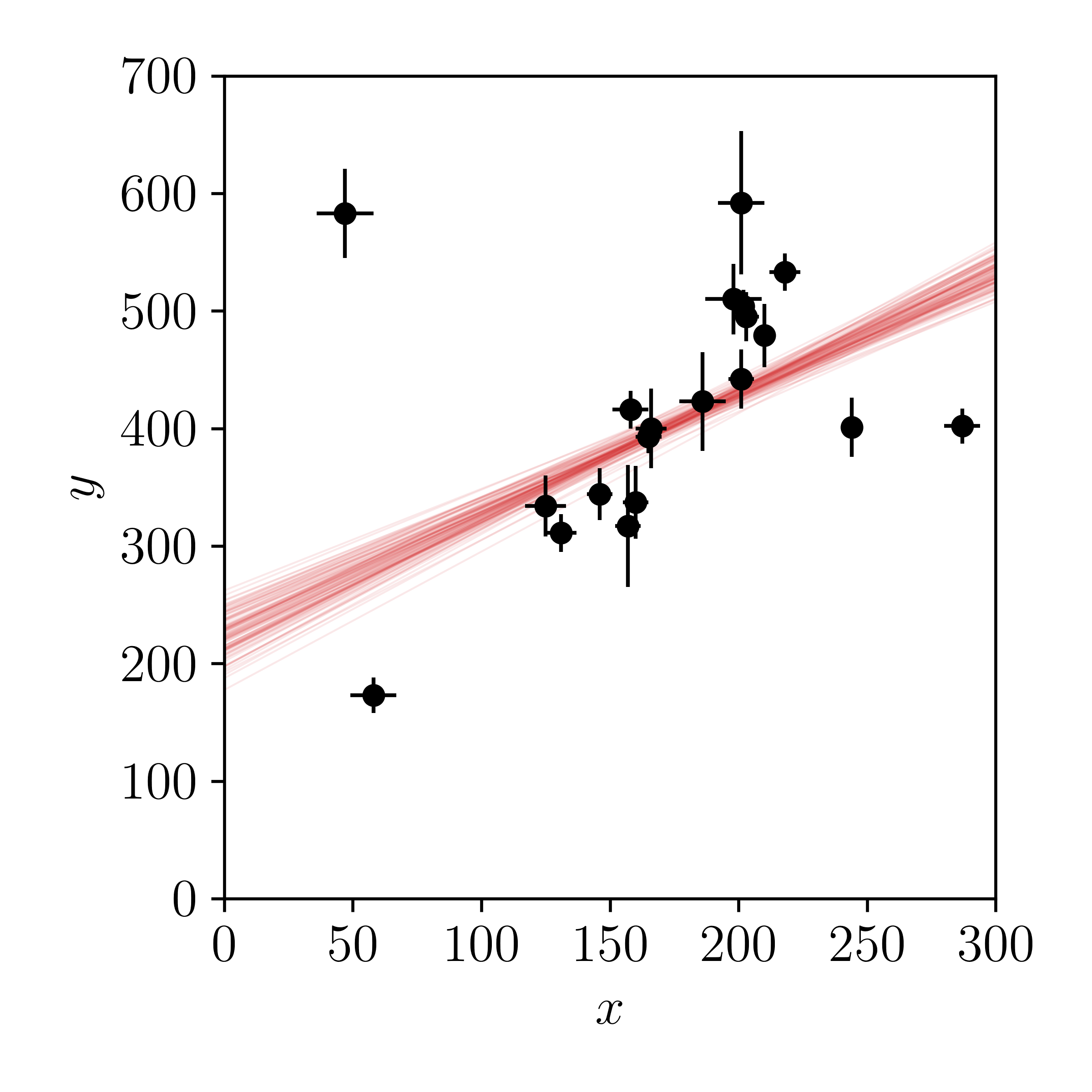
What do you think about this? Has including a prior on \(m\) and the uncertainties in the \(x\) direction made for a better model? Is it flexible enough? Probably not, since we know that the \(x\) and \(y\) truly aren't independent of each other.
Arbitrary two-dimensional uncertainties
Now we will consider the situation where the uncertainties in \(x\) and \(y\) are correlated. For a single data point \((x_i, y_i)\) with \(x\)-direction uncertainties \(\sigma_{xi}\), \(y\)-direction uncertainties \(\sigma_{yi}\), and a correlation coefficient \(\rho_{xy}\), the full covariance matrix is \[ \mathbf{C}_i \,=\, \left[\begin{array}{cc} \sigma_{xi}^2 & \rho_{xy,i}\sigma_{xi}\sigma_{yi} \\ \rho_{xy,i}\sigma_{xi}\sigma_{yi} & \sigma_{yi}^2 \end{array} \right] \quad . \] There are a few ways you could address this problem. We will start by introducing the residual vector \(\mathbf{R}_i\) for the \(i\)-th data point \[ \mathbf{R}_i \,=\, \left[ \begin{array}{c} x_i - \hat{x}_i \\ y_i - m\hat{x}_i - b \end{array} \right] \] such that the probability density function is \[ \newcommand{\transpose}{^{\scriptscriptstyle \top}} p(\vecdata,\vecx|m,b,\hat{\vecx},\mathbf{C}) = \prod_{i=1}^{N}\frac{1}{2\pi\sqrt{\det{\left(\mathbf{C}_i\right)}}}\exp{\left(-\frac{1}{2}{\mathbf{R}_i}\transpose{\mathbf{C}_i}^{-1}\mathbf{R}_i\right)} \] where we regretably overload our nomenclature by describing \(\mathbf{C}\) as the set of all covariance matrices, whereas \(\mathbf{C}_i\) describes the \(i\)-th covariance matrix.
Like earlier, we integrate over the true \(\hat{x}_i\) values for a single data point \[ p(y_{i},x_{i}|m,b,\mathbf{C}_n) = \int_{-\infty}^{+\infty} p(\hat{x}_{i})p(y_i,x_i|m,b,\hat{x}_i,\mathbf{C}_i)d\hat{x}_i \] using an (improper) uniform prior \[ p(y_i,x_i|m,b,\mathbf{C}_i) = \int_{-\infty}^{+\infty}\frac{1}{2\pi\sqrt{\det{\left(\mathbf{C}_i\right)}}}\exp\left(-\frac{1}{2}{\mathbf{R}_i}\transpose\mathbf{C}^{-1}\mathbf{R}_{i}\right)d\hat{x}_i \] such that the marginalised probability density is \[ p(y_i,x_i|m,b,\mathbf{C}_i) \propto \frac{1}{\sqrt{2\pi{\Sigma_i}^2}}\exp{\left(-\frac{{\Delta_i}^2}{2{\Sigma_i}^2}\right)} \] where \[ \begin{array}{ccl} \Delta_i &=& y_i - mx_i - b\\ {\Sigma_i}^2 &=& \left(\sigma_{xi}m\right)^2 - 2m\rho_{xy,i}\sigma_{xi}\sigma_{yi} + \sigma_{yi}^2 \end{array} \] or \[ {\Sigma_i}^2 \,=\, \mathbf{V}\transpose\mathbf{C}_i\mathbf{V} \] where \(\mathbf{V}\transpose = \left[-m \,\,\,1\right]\) is a projection vector.
Let's use the same prior on \(p(m,b)\) as earlier and sample the marginalised posterior probability (marginalised over \(\hat{x}_i\) values).
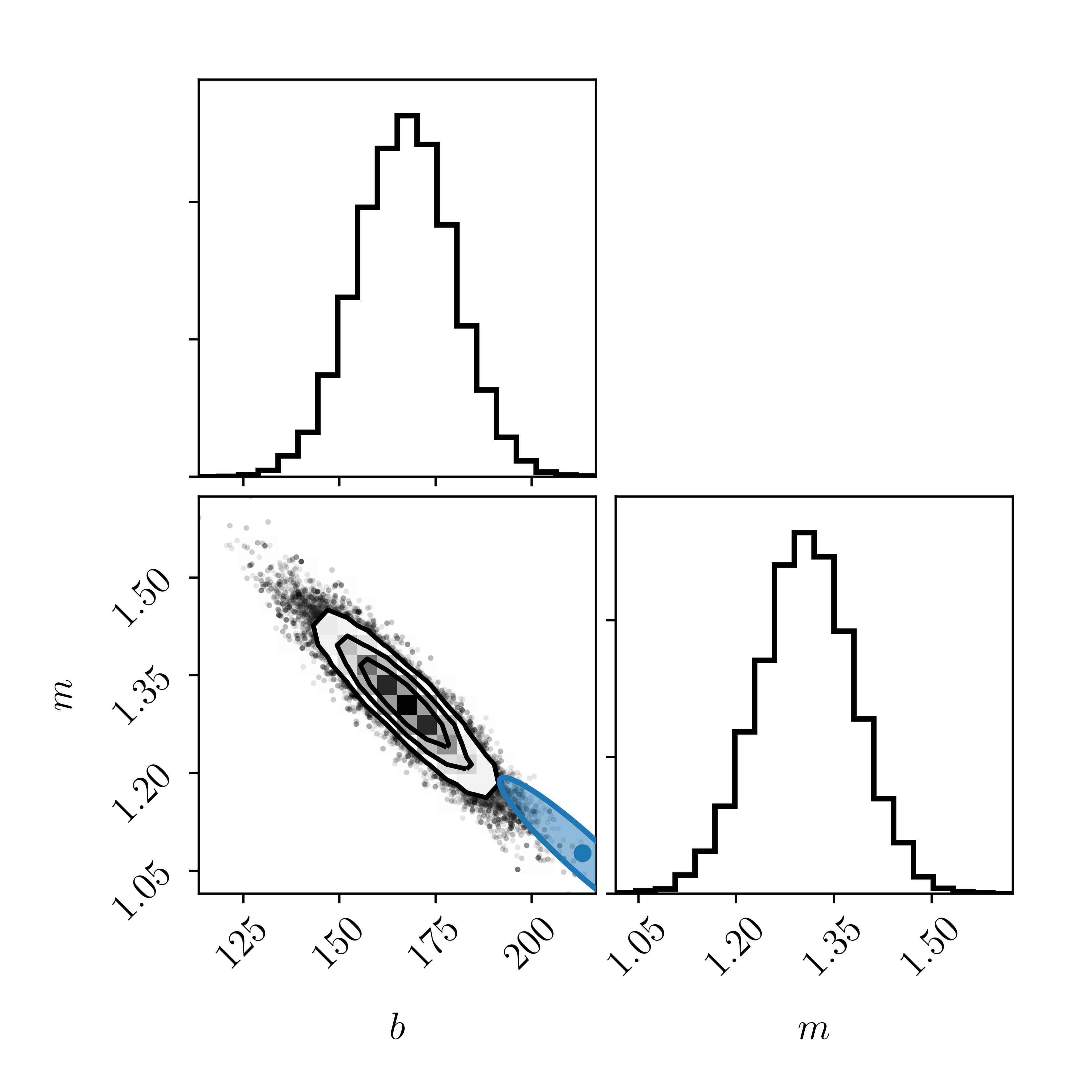
Wow! Compare the posteriors we get on \(m\) and \(b\) by including arbitrary uncertainties (i. e., the correlations between \(x\) and \(y\)) with the uncertainties we found in lesson one using linear algebra (blue). Now the two sets are barely consistent with each other!
Let's make posterior predictions of the line by drawing samples from the posterior and plotting the model predictions.

How else do these posteriors vary from what found in the last class from linear algebra? How do these posteriors change from what we did not include correlations in the \(x\) and \(y\) directions? Intuitively, what would you expect when you include, or do not include, correlations between uncertainties?
Intrinsic scatter
So far we have shown how to incorporate uncertainties in the \(x\) and \(y\) directions in different cases. The simpler case is when the uncertainties between \(x\) and \(y\) are uncorrelated, and in the more complex case the uncertainties are correlated. But in both cases we are still assuming that the data are generated from an infinitely narrow straight line, where any deviations from that line are entirely due to the uncertainties in the measurements.
What if that is not the case? What if the \(y\) values are described by a straight line relationship that depends on \(x\), but there is some intrinsic scatter, or jitter, to that relationship, such that deviations from the line are not only dependent on the measurement uncertainties?
Consider this possibility carefully. We're about to go through the math for this model, but first you should ask: How would I put a prior on the intrinsic scatter? Do you think you could place some prior on \(p(m,b)\) that would result in a small intrinsic scatter along the line? Why or why not? Write down that prior.
At this point many students find it useful to reconsider what they think of the term uncertainty. Uncertainty and error are not the same thing. Errors are mistakes. Data have uncertainties, not errors. If you appreciate that data are uncertain then you will feel more comfortable to learn that models can also be uncertain. What does this mean? I don't mean that model parameters are uncertain,
Let's do that. We will introduce a parameter that describes some intrinsic variance to the straight line relationship. Which direction should this intrinsic variance project to? The \(x\) direction? \(y\)? The answer is both: we want the intrinsic variance to be projected orthogonal to the line.
There are a few ways to parameterise this model. I like Dan Foreman-Mackey's nomenclature
We will state that the measured \(x\) and \(y\) values are drawn from a two-dimensional multivariate normal distribution such that \[ \left(\begin{array}{c} x_i \\ y_i \end{array} \right) \sim \mathcal{N}\left(\left[\begin{array}{c} \hat{x}_i \\ m\hat{x}_i + b \end{array}\right],\mathbf{\Lambda}\right) \] where \(\mathbf{\Lambda}\) is our two-dimensional covariance matrix that we will define later. Thanks to the sheer magic of Gaussians, the expected frequency distribution is \[ p(y_i,x_i|m,b,\hat{x}_i,\mathbf{C}_i,\mathbf{\Lambda}) = \frac{1}{2\pi\sqrt{\det{\left(\mathbf{C}_i + \mathbf{\Lambda}\right)}}}\exp\left(-\frac{1}{2}{\mathbf{R}_i}\transpose\left(\mathbf{C}_i + \mathbf{\Lambda}\right)^{-1}\mathbf{R}_i\right) \quad . \]
Integrating out \(\hat{x}_i\) as before leaves \[ p(y_i,x_i|m,b,\mathbf{C}_i,\mathbf{\Lambda}) \propto \frac{1}{\sqrt{2\pi{\Sigma_i}^2}}\exp\left(-\frac{{\Delta_i}^2}{2{\Sigma_i}^2}\right) \] where \(\Delta_i = y_i - mx_i - b\) as before but \[ {\Sigma_i}^2 \,=\, \mathbf{V}\transpose\left(\mathbf{C}_i + \mathbf{\Lambda}\right)\mathbf{V} \quad . \]
We still need to define \(\mathbf{\Lambda}\).
The intrinsic scatter \(\lambda\) will be projected orthogonal to the line, but we will still need to choose a prior on \(\lambda\). It's common to use a uniform prior in log-space
Ok, let's code it up.
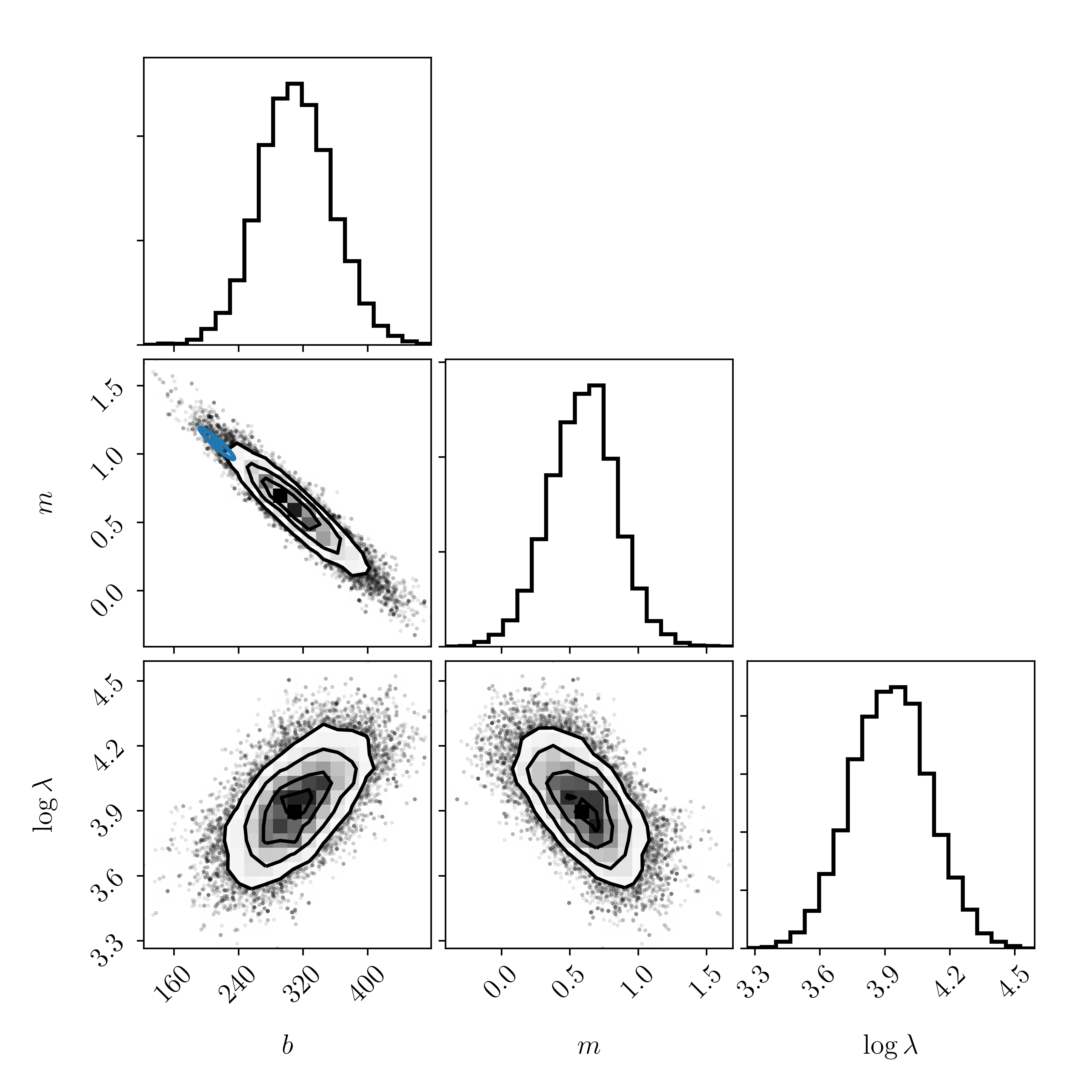
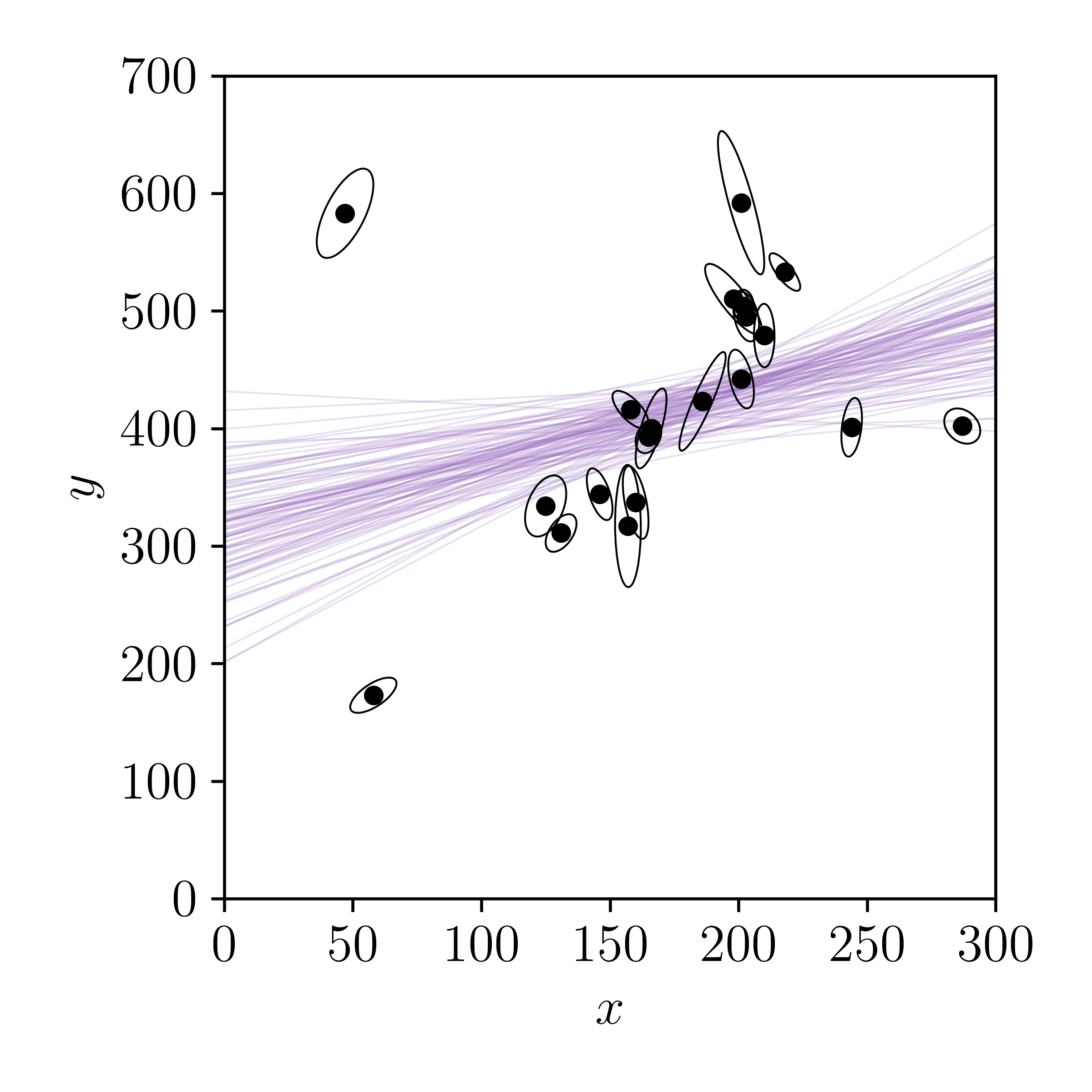
How does this result compare to our previous results where we did not consider uncertainties in the \(x\) direction, and where we did not include intrinsic scatter? Is the fit better or worse to you? Does the model uncertainty look reasonable, given the data? Is the model uncertainty realistic? Are our priors reasonable, or is there a lot of posterior support at the edges? What descriptive change do you want to make to this model so that it is more realistic, or more in line with your expectations?
In the next class we will discuss the concept of outliers, and how to objectively treat them using a mixture model.